
compliments of Cyrus Shepard | Moz.com
“What is this page about?”
As marketers, helping search engines answer that basic question is one of our most important tasks. Search engines can’t read pages like humans can, so we incorporate structure and clues as to what our content means. This helps provide the relevance element of search engine optimization that matches queries to useful results.
Understanding the techniques used to capture this meaning helps to provide better signals as to what our content relates to, and ultimately helps it to rank higher in search results. This post explores a series of on-page techniques that not only build upon one another, but can be combined in sophisticated ways.
While Google doesn’t reveal the exact details of its algorithm, over the years we’ve collected evidence from interviews, research papers, US patent filings and observations from hundreds of search marketers to be able to explore these processes. Special thanks to Bill Slawski, whose posts on SEO By the Sea led to much of the research for this work.
As you read, keep in mind these are only some of the ways in which Google could determine on-page relevancy, and they aren’t absolute law! Experimenting on your own is always the best policy.
We’ll start with the simple, and move to the more advanced.
1. Keyword Usage
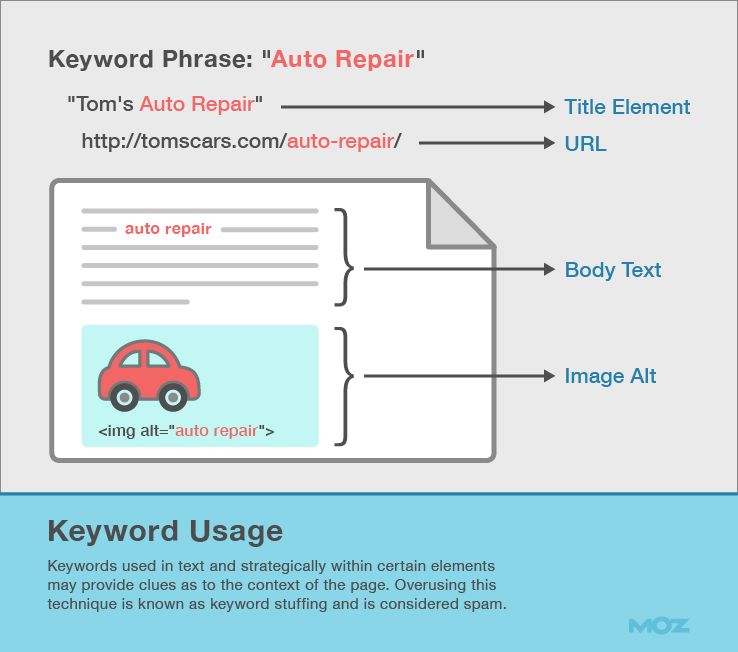
In the beginning, there were keywords. All over the page.
The concept was this: If your page focused on a certain topic, search engines would discover keywords in important areas. These locations included the title tag, headlines, alt attributes of images, and throughout in the text. SEOs helped their pages rank by placing keywords in these areas.
Even today, we start with keywords, and it remains the most basic form of on-page optimization.
Most on-page SEO tools still rely on keyword placement to grade pages, and while it remains a good place to start, research shows its influence has fallen.
While it’s important to ensure your page at a bare minimum contains the keywords you want to rank for, it is unlikely that keyword placement by itself will have much of an influence on your page’s ranking potential.
2. TF-IDF
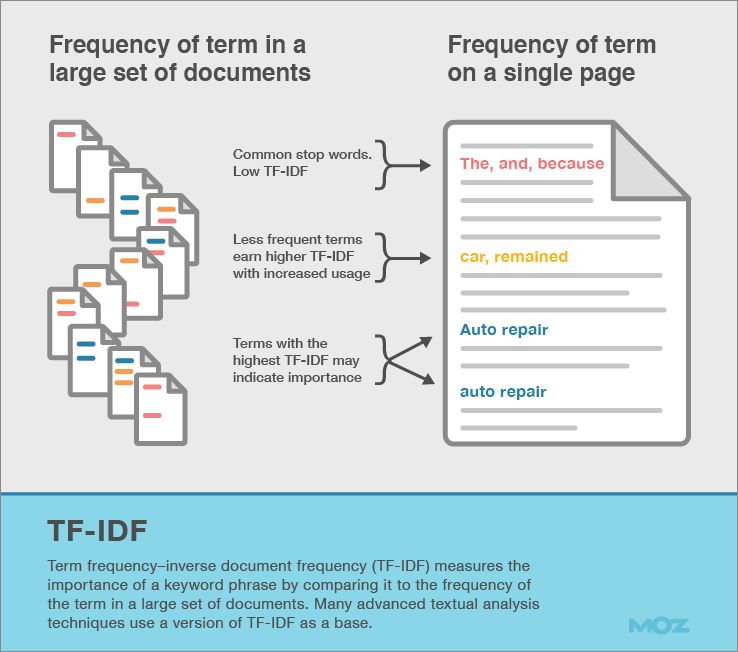
It’s not keyword density, it’s term frequency–inverse document frequency (TF-IDF).
Google researchers recently described TF-IDF as “long used to index web pages” and variations of TF-IDF appear as a component in several well-known Google patents.
TF-IDF doesn’t measure how often a keyword appears, but offers a measurement of importance by comparing how often a keyword appears compared to expectations gathered from a larger set of documents.
If we compare the phrases “basket” to “basketball player” in Google’s Ngram viewer, we see that “basketball player” is a more rare, while “basket” is more common. Based on this frequency, we might conclude that “basketball player” is significant on a page that contains that term, while the threshold for “basket” remains much higher.
For SEO purposes, when we measure TF-IDF’s correlation with higher rankings, it performs only moderately better than individual keyword usage. In other words, generating a high TF-IDF score by itself generally isn’t enough to expect much of an SEO boost. Instead, we should think of TF-IDF as an important component of other more advanced on-page concepts.
3. Synonyms and Close Variants
With over 6 billion searches per day, Google has a wealth of information to determine what searchers actually mean when typing queries into a search box. Google’s own research shows that synonyms actually play a role in up to 70% of searches.
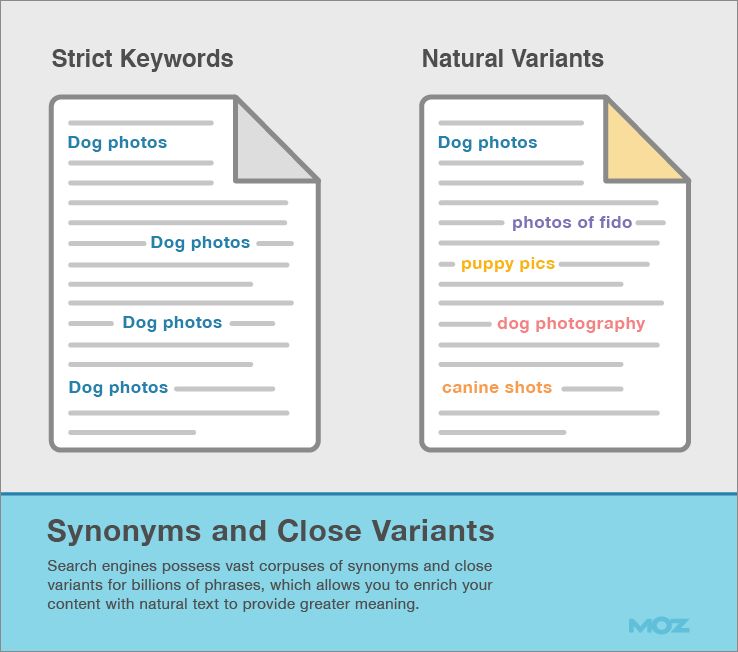
To solve this problem, search engines possess vast corpuses of synonyms and close variants for billions of phrases, which allows them to match content to queries even when searchers use different words than your text. An example is the query dog pics, which can mean the same thing as:
• Dog Photos • Pictures of Dogs • Dog Pictures • Canine Photos • Dog Photographs
On the other hand, the query Dog Motion Picture means something else entirely, and it’s important for search engines to know the difference.
From an SEO point of view, this means creating content using natural language and variations, instead of employing the same strict keywords over and over again.
Today, Google’s Hummingbird algorithm also uses co-occurrence to identify synonyms for query replacement.
Under Hummingbird, co-occurrence is used to identify words that may be synonyms of each other in certain contexts while following certain rules according to which, the selection of a certain page in response to a query where such a substitution has taken place has a heightened probability.
Bill Slawski – SEO by the Sea
4. Page Segmentation
Where you place your words on a page is often as important as the words themselves.
Each web page is made up of different parts—headers, footers, sidebars, and more. Search engines have long worked to determine the most important part of a given page. Both Microsoft and Google hold several patents suggesting content in the more relevant sections of HTML carry more weight.
Content located in the main body text likely holds more importance than text placed in sidebars or alternative positions. Repeating text placed in boilerplate locations, or chrome, runs the risk of being discounted even more.
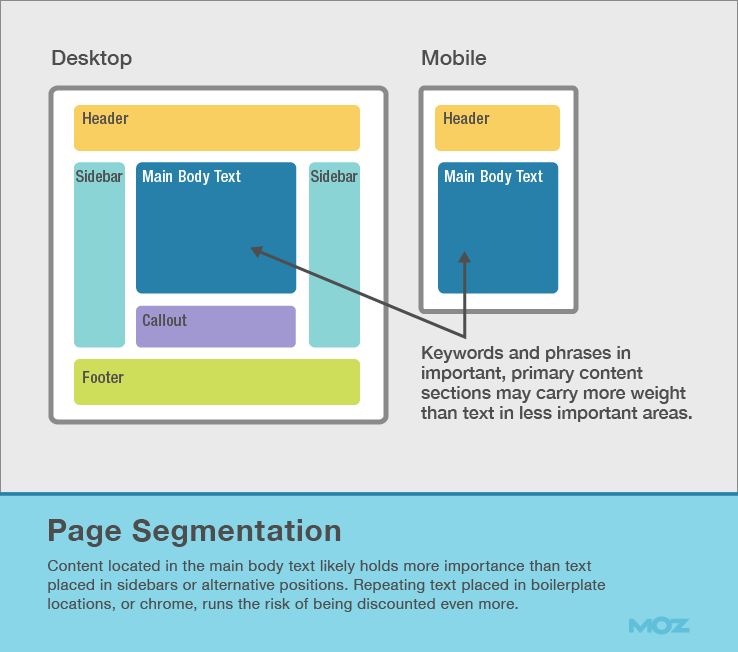
Page segmentation becomes significantly more important as we move toward mobile devices, which often hide portions of the page. Search engines want to serve users the portion of your pages that are visible and important, so text in these areas deserves the most focus.
To take it a step further, HTML5 offers addition semantic elements such as,, and, which can clearly define sections of your webpage.
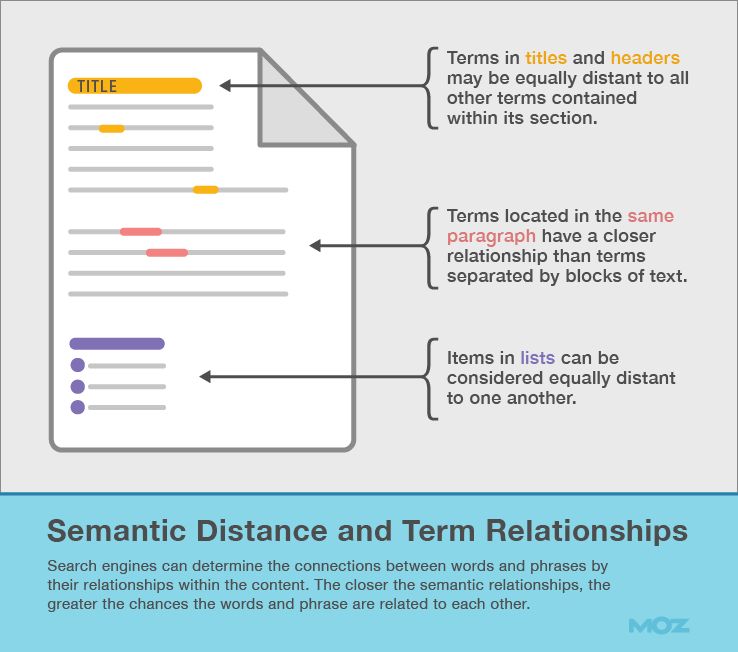
5. Semantic Distance and Term Relationships
When talking about on-page optimization, semantic distance refers to the relationships between different words and phrases in the text. This differs from the physical distance between phrases, and focuses on how terms connect within sentences, paragraphs, and other HTML elements.
How do search engines know that “Labrador” relates to “dog breeds” when the two phrases aren’t in the same sentence?
Search engines solve this problem by measuring the distance between different words and phrases within different HTML elements. The closer the concepts are semantically, the closer the concepts may be related. Phrases located in the same paragraph are closer semantically than phrases separated by several blocks of text.
Now is a good time to mention Schema.org. Schema markup provides a way to semantically structure portions of your text in a manner that explicitly define relationship between terms.
The great advantage schema offers is that it leaves no guesswork for the search engines. Relationships are clearly defined. The challenge is it requires webmasters to employ special markup. So far, studies show low adoption. The rest of the concepts listed here can work on any page containing text.
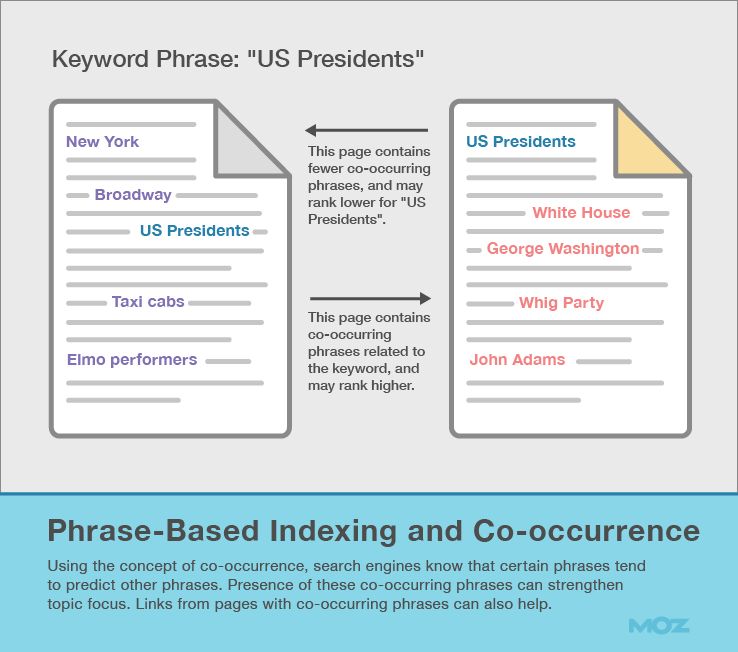
6. Co-occurrence and Phrase-Based Indexing
Up to this point, we’ve discussed individual keywords and relationships between them. Search engines also employ methods of indexing pages based on complete phrases, and also ranking pages on the relevance of those phrases.
We know this process as phrase-based indexing.
What’s most interesting about this process is not how Google determines the important phrases for a webpage, but how Google can use these phrases to rank a webpage based on how relevant they are.
Using the concept of co-occurrence, search engines know that certain phrases tend to predict other phrases. If your main topic targets “John Oliver,” this phrase often co-occurs with other phrases like “late night comedian,” “Daily Show,” and “HBO.” A page that contains these related terms is more likely to be about “John Oliver” than a page that doesn’t contain related terms.
7. Entity Salience
Looking to the future, search engines are exploring ways of using relationships between entities, not just keywords, to determine topical relevance.
One technique, published as a Google research paper, describes assigning relevance through entity salience.
Entity salience goes beyond traditional keyword techniques, like TF-IDF, for finding relevant terms in a document by leveraging known relationships between entities. An entity is anything in the document that is distinct and well defined.
The stronger an entity’s relationship to other entities on the page, the more significant that entity becomes.
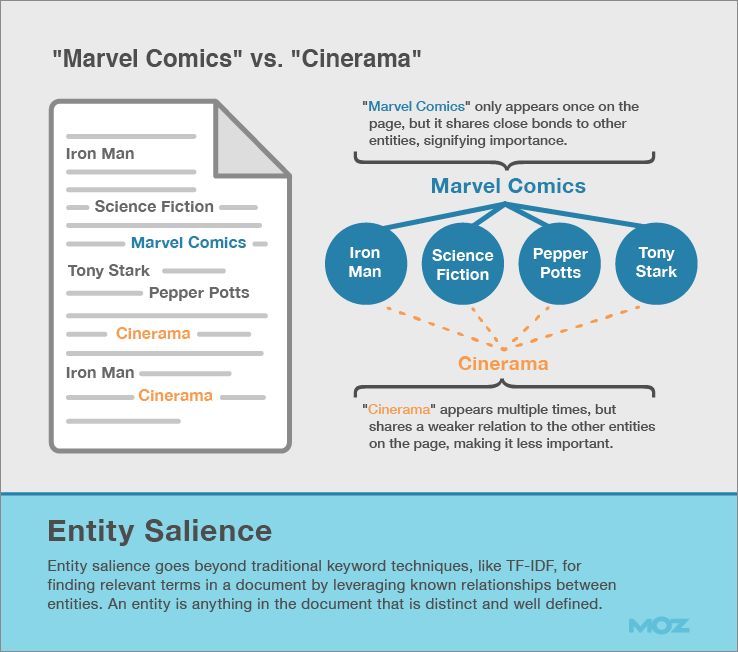
On the other hand, even though the phrase “Cinerama” appears multiple times (because the film showed there), this phrase has weaker entity relationships, and likely isn’t as significant.
Practical tips for better on-page optimization
As we transition from keyword placement to more advanced practices of topic targeting, it’s actually easy to incorporate these concepts into our content. While most of us don’t have the means available to calculate semantic relationships and entity occurrences, there are a number of simple steps we can take when crafting optimized content:
Keyword research forms your base. Even though individual keywords themselves are no longer enough to form the foundation of your content, everything begins with good keyword research. You want to know what terms you are targeting, the relative competition around those keywords, and the popularity of those terms. Ultimately, your goal is to connect your content with the very keywords people type and speak into the search box.
Research around topics and themes. Resist researching single keywords, and instead move towards exploring your keyword themes. Examine the secondary keywords related to each keyword. When people talk about your topic, what words do they use to describe it? What are the properties of your subject? Use these supporting keyword phrases as cast members to build content around your central theme.
When crafting your content, answer as many questions as you can. Good content answers questions, and semantically relevant content reflects this. A top ranking for any search query means the search engine believes your content answers the question best. As you structure your content around topics and themes, make sure you deserve the top ranking by answering the questions and offering a user experience better than the competition.
Use natural language and variations. During your keyword research process, it’s helpful to identify other common ways searchers refer to your topic, and include these in your content when appropriate. Semantic keyword research is often invaluable to this process.
Place your important content in the most important sections. Avoid footers and sidebars for important content. Don’t try to fool search engines with fancy CSS or JavaScript tricks. Your most important content should go in the places where it is most visible and accessible to readers.
Structure your content appropriately. Headers, paragraphs, lists, and tables all provide structure to content so that search engines understand your topic targeting. A clear webpage contains structure similar to a good university paper. Employ proper introductions, conclusions, topics organized into paragraphs, spelling and grammar, and cite your sources properly.
At the end of the day, we don’t need a super computer to make our content better, or easier to understand. If we write like humans for humans, our content goes a long way in becoming optimized for search engines.
Special thanks to Dawn Shepard, who provided the images for this post.
About Cyrus-Shepard — Cyrus Shepard is an SEO who works as Director of Audience Development for Moz. See his profiles on Twitter, LinkedIn, Facebook, Google+, and Slideshare.
![]()